

What is ODF?
Ocean Data Factory (ODF) Sweden, started in July 2019, is an initiative at the intersection of industry, academia and the public sector to liberate data from our oceans. ODF Sweden is a part of Vinnova’s investment to speed up national development within AI. The project has two main objectives: to build broader AI competence and to encourage innovation. At the heart of this mission is a principle of openness that encourages broad cross-disciplinary participation from anyone eager to use ocean data to address ocean challenges.
For more information visit the ODF Sweden website here
General approach to use cases
Once ODF Sweden has selected a use case for further investigation, the methodology for AI implementation follows a key series of iterative steps:
- Data collection
- Data preparation and cleaning
- Setup of training, validation and test sets
- Training the models
- Evaluating model using suitable targets
- Interpreting model output
- Continue until output is actionable
During the first six months, our team focused mainly on the use case of the invasive species Dikerogammarus Villosus in the Baltic Sea region.
Use case 1: Invasive Species D. Villosus

Initial problem formulation:
- The killer shrimp’s (D. Villosus) presence has been recorded in rivers in Western Europe,
- presumably by travelling through inland waterways from the Black Sea, and
- assumed to be carried by cargo ships where ocean expanses are too vast to traverse.
Research Question:
Can Machine Learning methods help us predict the areas of the Baltic sea which would be suitable for the Killer Shrimp?
Data used
- Presence data from the North Sea & Baltic Sea regions (roughly 3000 data points)
- Pseudo-absence data from the Baltic Sea region (2.8 million data points)
- Environmental rasters for key environmental drivers informed by subject experts which include: surface temperature, surface salinity, substrates, exposure and depth (averaged during the winter months, where appropriate).

Figure 2: Raster feature layers stacked onto a basemap [2] Finding a needle in a haystack
There is an extreme class imbalance in the presence-absence data that merits additional caution when applying any machine learning classifier. In this case, a naive classifier would have an accuracy of roughly 99.9% if it simply always chooses the majority class – “Absent”.
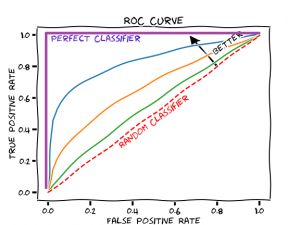
Figure 3: Confusion matrix with some common evaluation metrics To evaluate model performance in a more useful way, we also consider the importance of each class. In this case, finding all the presence locations is more crucial than missing out on some absence locations, i.e. we can accept more False Postives (FP) than False Negatives (FN). In other words, we favour maximising the Recall score over the Precision score, which tells us how successful we are at identifying the presence locations. To evaluate this trade-off, we use the AUROC (Area under Receiver Operating Curve) which tells us how well our model discriminates between these two classes.
Figure 3: ROC curve example [3] By looking at these metrics, we can separate naive majority classifier models (with an AUROC close to 0.5) from models that choose appropriate features to improve our classification performance on the positive (“Presence”) class (AUROC above 0.8).
Models used
Tree-based models (single and ensemble) seemed most appropriate as no feature selection or pre-processing had to be performed and could thus avoid such biases. In addition, tree-based models are easier to interpret which allows us to directly investigate model predictions and understand underlying driving factors.
We also opted for a deep feed-forward neural network in order to capture more complex features than those provided by tree-based models alone.
Results
| Model | Accuracy | AUROC | F1 | Recall |
| ———– | ———– | ———– | ———– | ———– |
| Majority Classifier| 0.999 | 0.500 | 0.000 | 0.000 |
| Decision Tree| 0.999 | 0.917 | 0.833 | 0.833 |
| Random Forest | 0.999 | 0.917 | 0.810 | 0.833 |
| Deep Neural Network | 0.999 | 0.958 | 0.059 | 0.917 |When we consider the AUROC and Recall metrics, we see that the Neural Network manages to outperform both other models. We also see that the strong F1 scores attached to the Decision Tree and Random Forest models were mainly due to their preference to predict the majority class.
Evaluating model decisions
Figure 4: Example of tree model decision on one test case based on SHAP values Decision tree models allow us to look “under the hood” and see how individual features contribute to decisions.
In this case, we make use of SHAP values first discussed by Lundberg and Lee [3] which use a game-theoretic approach to explain the contribution of each feature to the prediction. In Figure 4, we see both the magnitude and direction of the average impact of a feature on the decision to classify this case as “Absent”. Some notable factors are that we have a sandy substrate (denoted by 1 in this model), and that the temperature is outside the normal range, but most of all the depth is out of the normal range of the D. Villosus which pushes towards the absence outcome.
Visualising model predictions and the potential impacts of climate change
Since our features come in the form of rasters (which are grids of cells with feature values), using our trained models we are able to make predictions for each cell in the raster grid. The output from the model is then the probability of “presence” in that cell. Below, we have built a web application that helps us visualise the probabilities from some of these models, as well as the impact of future climate changes on these probabilities in the Baltic Sea. Specifically, notice the increased suitability of Åland and the Eastern Coast of Sweden (Östersjön) under future climate condition forecasts provided by the Swedish Meteorological Services (SMHI), one of the partners of ODF Sweden.
Key takeaways
- GIS modelling involves domain knowledge of the underlying phenomena which becomes very important for model output interpretation.
- Data, data, data… The more data, the better our choices of models and the richer our potential insights.
- Documentation of methods and data extraction methods is crucial to communicate methods and ideas to groups from a wide range of backgrounds.
- Results should always be critically approached since assumptions about the data and the models strongly impact the model outcomes and success criteria.
- The methods used have demonstrated that useful insights can be generated, which has raised many other interesting questions. For example, given the direction of currents along a particular coastline, which paths become most probable for shrimp migration?
Try it out on Kaggle:
Our progress has been fully documented on Kaggle Notebooks to encourage further discussion and collaboration:
- Invasive Species Notebook
- Invasive Species Notebook v2
Next steps
* The nature of this project is that our problems continually evolve in line with our ability to access an increasing amount of data and better understand the important questions that need answering. This is clear in the transition of our methods from Notebook v1 to Notebook v2 in Kaggle. Our hope is that this will continue as outside participation increases and more data becomes available.
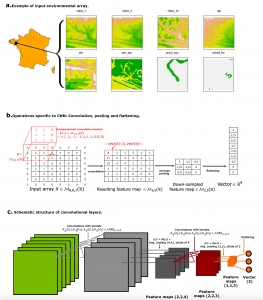
* One avenue we are exploring is to expand the current deep learning model to raster features using a convolutional approach because there are spatial correlations in rasters that make our pointwise model costly and inefficient. This would allow us to also forecast abundance figures and not simply presence, and answer a host of other questions (e.g. predicting raster density landscapes). To achieve this, we would need to significantly increase our data, either through collecting more data or augmenting the data we currently have. Figure 5 below illustrates what such a model might look like:
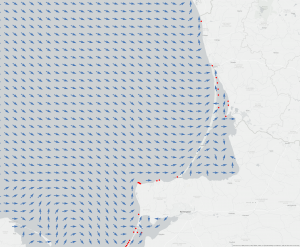
Figure 5: A convolution model proposed by Christophe Botella, Alexis Joly, Pierre Bonnet, Pascal Monestiez, François Munoz. [4] * Another future aim is to have a better understanding of the migration pattern of this species, which so far is assumed to travel through shipping traffic, but whose presence in particular parts of the Baltic Sea seem to show that there is more to the story. For e.g., recent data on currents in the Baltic sea along the coasts of Poland and Kaliningrad seem to show how currents drive migration of Killer Shrimp in this region.
Figure 6: Illustration of currents in the Baltic Sea along with presence of D. Villosus (in red) * Lastly, it is crucial that we continue to document and share the progress made and challenges encountered. In this way, we may be able to identify the lessons learned that are applicable to invasive species in general and those which apply specifically to this case so that methods may be carried over to new problems in ODF Sweden and beyond.
References:
[2]https://www.oceanecology.ca/species_model_data.jpg
[3] https://commons.wikimedia.org/wiki/File:Roc-draft-xkcd-style.svg


![[1]https://upload.wikimedia.org/wikipedia/commons/thumb/0/03/Scheme_amphipod_anatomy-en.svg/220px-Scheme_amphipod_anatomy-en.svg.png](https://upload.wikimedia.org/wikipedia/commons/thumb/0/03/Scheme_amphipod_anatomy-en.svg/220px-Scheme_amphipod_anatomy-en.svg.png ){kind=link}
![[3] https://commons.wikimedia.org/wiki/File:Roc-draft-xkcd-style.svg](https://commons.wikimedia.org/wiki/File:Roc-draft-xkcd-style.svg.){kind=link}